Why NoSQL?
DynamoDB is a distributed system: Any-Scale Global Web application with minimal management.

This is from a media company for the 2017 Superbowl was provisioned at 5.5m WCUs(Write Capacity Units), traffic hit 10+ mil at the end of the game! Traffic went from 3.5M WCUs to 10M WCUs in a 1 minute period and then back down to 3.5M. (over consumption is also allowed due to burst capacity)
Performance at any scale
DynamoDB provides not only high throughput, but also consistent and very predictable responsiveness.
Every event router in the fleet caches your information and doesn’t need to look up where your storage nodes are.
SQL and No SQL side by side
| SQL | NoSQL |
| Optimized for storage | Optimized for compute |
| Normalized/relational | Denormalized/hierarchical |
| Ad hoc queries | Instantiated views |
| Scale vertically | Scale horizontally |
| Good for OLAP | Built for OLTP at scale |
An OLTP workload is where 90-95% of access is predefined patterns, we can solve for the 5-10% of 'other' queries with other solutions which will be described later. Example of OLTP: supporting shopping cart or session service for millions of users during a large scale online sale event.
Scaling Databases
NoSQL delivers on the promise of massive scale by using horizontal scaling, where data and workload are partitioned over a number of shards that can grow as the data volume and throughput grow. Scaling is incremental, which means more nodes/partitions are added as needed.
If this is done right, the performance does not change as the data and throughput grow. Performance at scale was one of the main goals for NoSQL databases - that was certainly true for Amazon DynamoDB.
There are two parts to doing this right:
- the technology has to be able to do it.
- the user has to deploy a good partitioning schema
Why DynamoDB?
Amazon DynamoDB
- Fully managed database, you don’t need to spin up server instances, install software, manage failovers, upgrade software or any other basic database maintenance tasks.
- Key-value store or Document database.
- All requests to DynamoDB are made to the DynamoDB API via HTTP requests. This is in contrast to most database systems that initialize persistent TCP connections that are reused many times over the lifetime of an application. Persistent connections have downsides as well, holding a persistent connection requires resources on the database server, so most databases limit the number of open connections to a database.
- Infrastructure as code friendly: Provisioning, updating, removing infrastructure can be done in an automatic fashion instead of manual steps by an engineer.
DynamoDB is designed to be used as an operational database in OLTP use cases where you know access patterns and can design your data model for those access patterns.
There are some of the things that DynamoDB can bring to your applications.
- Fully managed, cloud-native NoSQL database service
- Designed for mission-critical OLTP use cases where you know access patterns
- Operational database that provides:
- Extreme scale with horizontal scaling
- Consistent performance at any scale
- High availability and reliability
- Global availability and cross-region replication
- Full Serverless experience
- Easy integration with other AWS services
Adaptive Capacity
- Dynamic partitioning for storage and throughput
- Automatic isolation of frequently accessed items
- Automatic boosting if table is consuming less than provisioned
- On by default, no extra cost
The basic abstraction in DynamoDB is table.
To get started with DynamoDB, all you have to do is create a table, you don’t have to worry about selecting the right hardware for your database node or cluster. DynamoDB handles the resources behind the scenes.

DynamoDB horizontally shared a given table into 1 or more underlying partitions. It enables us to scale to many partitions across many servers. DynamoDB abstracts the virtual partitions so that you don’t have to worry about them: you use storage, read and write capacity and that’s what you think about.
Dynamic Partitioning - Storage Growth

The application is doing most of its writes to Partition A, meaning that Partition A’s storage is nearly full.

DynamoDB automatically partitions Partition A into two parts: Partition A, which stays on Server 1, and Partition B, which is placed on Server 2. This change is transparent to your application, and DynamoDB automatically sends requests to the new partition.
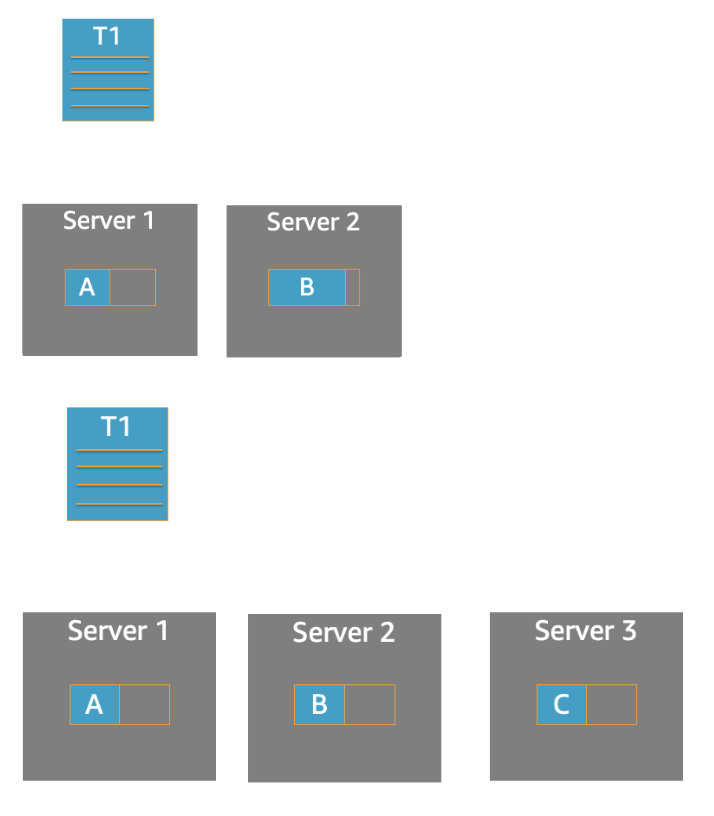
As your workload evolves, DynamoDB automatically reshards and dynamically redistributes your partitions in response to changes in read throughput, write throughput, and storage.
High-traffic item isolation
Isolate Frequently Accessed Items
If your application drives disproportionately high traffic to one or more items, adaptive capacity rebalances your partitions such that frequently accessed items don’t reside on the same partition. This isolation of frequently accessed items reduces the likelihood of request throttling due to your workload exceeding the throughput limit on a single partition.

If your application drives consistently high traffic to a single item, adaptive capacity might rebalance your data such that a partition contains only that single, frequently accessed item. In this case, DynamoDB can deliver throughput up to the partition maximum of 3,000 RCUs or 1,000 WCUs to that single item’s primary key.
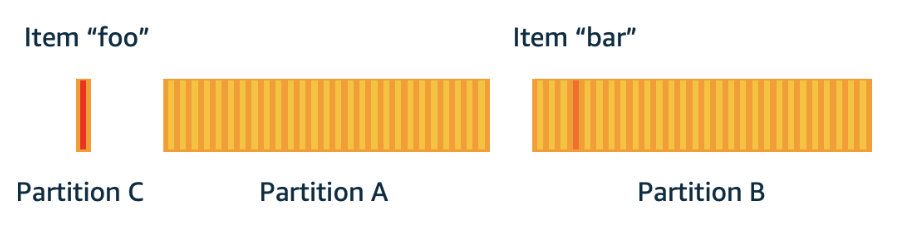
So Max RCU 3000 and WCU 1000 for each partition.
If the item “foo“ is read-heavy and needs more RCU, use DAX.
If the item “foo“ is write-heavy and need more WCU, use write-sharding patterns to distribute among more partitions.
Key Concepts
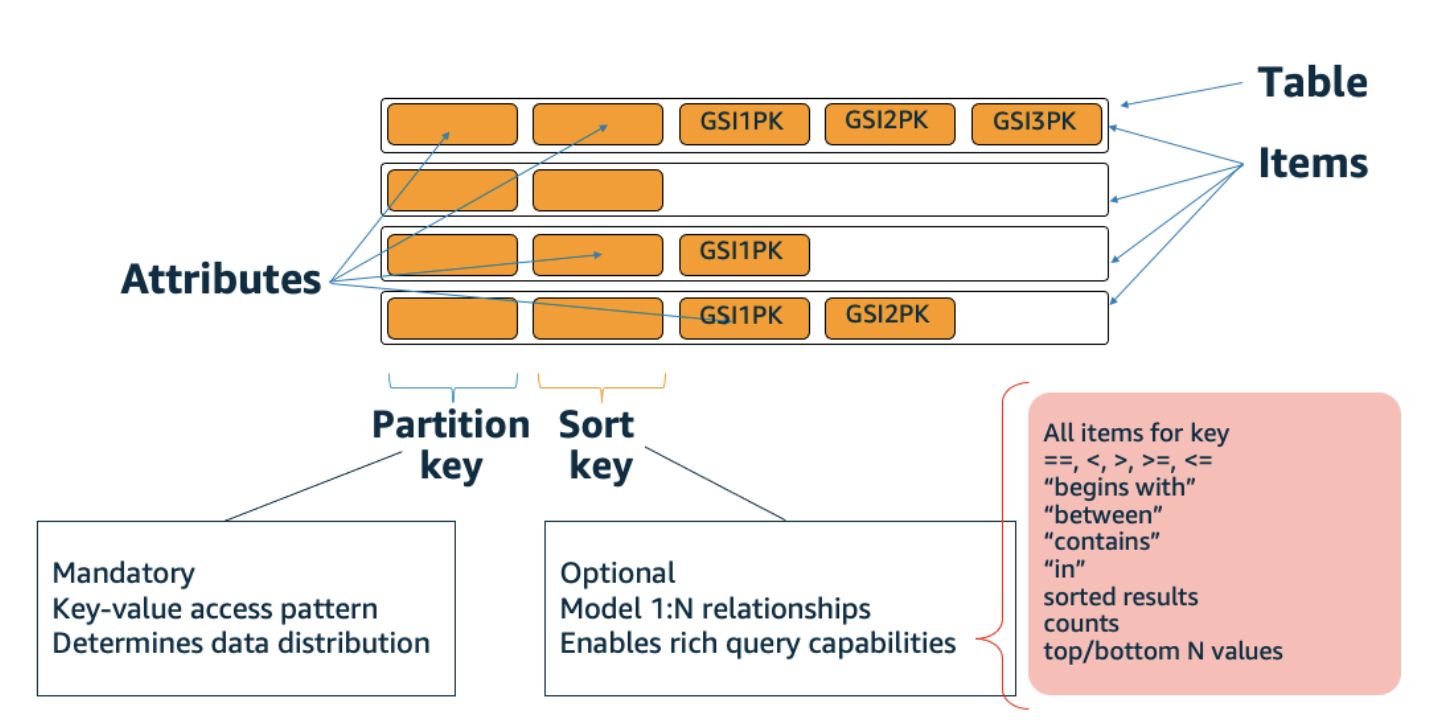
Example Data Modeling - Device Log

Global Secondary Index
GSI allows you to have an alternate schema on your DynamoDB table.

GSIs acts like a DyanmoDB table, make sure you have enough provisioned capacity, or use the DynamoDB on-demand mode.
DynamoDB responsible for copying data from your base table into your GSIs. It is asynchronously updated in milliseconds, depending on the situation.
You get up to 20 GSI per table, you choose whatever partition key you want.
Read/Write Capacity Modes
Provisioned Mode
- Specify the maximum amount of read and write capacity for a table or index
- Use auto scaling to adjust your table’s provisioned capacity automatically in response to traffic changes
On-demand Mode
- No capacity planning is required
- Pay per request pricing
You can switch between read/write capacity modes once every 24 hours.
Provisioned Mode
Auto Scaling
Auto Scaling is helping this customer to pay only for the throughput they need, and it is also protecting them from application impact due to under-provisioning if they should see an uncharacteristically high load.


Use Provision Mode
- Predictable workloads
- Gradual ramps
- Events with known traffic
- Ongoing monitoring
Use on-demand mode
- Unpredictable workloads
- Frequently idle workloads
- Events with unknown traffic
- “Set it and forget it“
Also consider your tolerance for operational overhead and overprovisioning


Amazon CloudWatch Contributor Insights for DynamoDB

Feature
- Key-level activity graphs
- 1-click integration
Key benefits
- Identify frequently accessed keys and traffic trends at a glance
- Respond appropriately to unsuccessful requests
DynamoDB Streams - Event-Driven Architecture

Streams are a change log – a message bus that persists for 24 hours, of ever mutation on the table. It delivers the items exactly once in order (by keyspace). There is a one to one partitions supporting a table to shards within a stream, in this sense it is very very similar to Kinesis – however, the items are automatically inserted into the stream from table.
These shards are then consumed using a KCL Worker (there is an adapter for the KCL library called the DynamoDB Adapter for KCL) or natively as a trigger for Lambda!
Sample Architecture:

References:
'고기 대신 SW 한점 > Public Cloud' 카테고리의 다른 글
| [AWS] Cluster Autoscaler (CA) (0) | 2023.01.04 |
|---|---|
| [AWS] WAF Managed Rule Set 적용 예 (0) | 2023.01.04 |
| [AWS] Amazon EKS Version - 2 (1) | 2022.12.22 |
| [AWS] Amazon EKS Version-1 (0) | 2022.12.22 |
| [AWS] InfraStructure -Amazon GuardDuty 설정하기 (0) | 2022.11.24 |