https://istio.io/latest/docs/tasks/observability/
Observability
Demonstrates how to collect telemetry information from the mesh.
istio.io
Observability vs Monitoring
외부 신호와 특성만 보고 시스템 안정적으로 동작하는지 확인하고 문제가 발생했을때 언제 잘못되었는지 어떤 이유인지 파악하기 위해 측정되는 시스템의 특성을 Observability라 얘기합니다. Observability는 런타임 동작을 변경할 수 있는 시스템에 대한 제어를 구현하는 데 중요합니다. 클라우드 인프라와 어플리케이션에서 생성하는 로그와 이벤트, 메트릭 등 모든것을 기록하고 관찰하는 것을 의미합니다.
Observability라는 용어는 이미 익숙한 용어인 모니터링 측면에서 분명하게 다른면이 있습니다. 모니터링은 메트릭, 로그, 트레이스 등을 수집, 집계하고 주의 깊게 관찰해야 하는 사전 정의된 시스템 상태와 일치하는지 측정하고 비교하는 행위를 말합니다. 측정항목 중 하나가 임계값을 초과하여 문제가 있음을 발견하면 시스템을 바로잡기 위한 조치를 취합니다.
모니터링은 Observability의 하위 구성요소입니다. 모니터링을 통해 정상 상태가 아닌 메트릭을 구체적으로 수집하고 집계하여 경고합니다. 반면, Observability은 시스템이 매우 예측 불가능하기 때문에 모든 장애 및 문제 상황을 미리 알 수는 없다고 가정합니다. 실제 시스템에 적용할때는 시스템의 안정성을 중시하면서 예측할 수 없는 문제가 언제 발생하는지 빨리 파악하고 이러한 동적인 상태를 유지하기 위해 적절한 수준의 자동으로 제어되는 시스템을 구축하는것을 목표로 합니다.
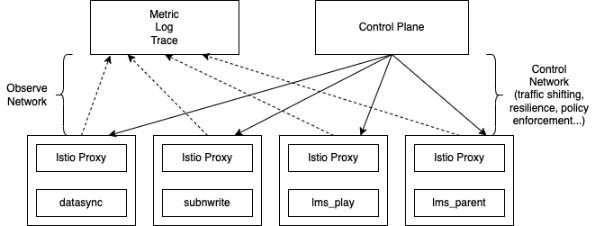
Istio의 데이터 플레인 프록시인 Envoy는 서비스 간의 네트워크 요청 경로에 있기 때문에 Istio는 관측가능한 시스템을 구축하는 데 도움이 되는 고유한 위치에 있습니다. Istio는 Envoy 서비스 프록시를 통해 초당 요청 수(requests per second), 요청 소요 시간(ms), 실패한 요청 수 등과 같은 서비스 상호 작용과 관련된 중요한 메트릭을 캡처할 수 있습니다.
또한 Istio는 시스템에 새로운 메트릭을 동적으로 추가하여 이전에 생각하지 못했던 새로운 데이터를 캡처할 수 있도록 합니다.
Istio observability
Istio 서비스 프록시는 서비스 경로에 위치하기 때문에, Istio는 애플리케이션 간에 일어나는 일에 대한 telemetry과 insight을 수집할 수 있습니다. Istio의 서비스 프록시는 각 애플리케이션과 함께 사이드카로 배포되므로, 이 프록시가 수집하는 정보는 애플리케이션의 "프로세스 외부(out of process)"에서 얻을 수 있습니다. 대부분의 경우 애플리케이션이 이러한 수준의 observability를 위해 라이브러리 또는 별도의 구현이 필요하지 않음을 의미합니다. 애플리케이션은 프록시에 대한 블랙박스이며 telemetry는 네트워크를 통해 관측되는 응용 프로그램의 동작에 초점을 맞춥니다.
Istio는 observability의 두 가지 주요 범주에 대한 telemetry을 만듭니다. 첫 번째는 초당 요청 수, failure 수, latencty 백분위수와 같은 최상위 메트릭입니다. 이러한 값을 통해 시스템에서 문제가 발생하기 시작하는 위치를 파악할 수 있습니다. 둘째, Istio는 OpenTelemetry와 같은 분산 추적을 용이하게 할 수 있습니다. Istio는 애플리케이션이 걱정할 필요 없이 tracing 백엔드로 span을 전송할 수 있습니다. 이렇게 하면 특정 서비스 통신간에 발생한 일을 자세히 살펴보고, latency이 발생한 위치를 확인하고, 전체 latency에 대한 정보를 얻을 수 있습니다.
위 그림처럼 데이터 플레인은 요청을 처리하고, 제어 플레인은 요청을 처리하도록 데이터 플레인을 구성합니다. 둘 다 애플리케이션 네트워크와 메쉬 운영 측면에서 런타임에 무슨 일이 일어나고 있는지 파악할 수 있는 각각의 메트릭 세트를 노출합니다.
Data Plane metrics
쿼리를 실행하여 Pod에서 직접 통계를 볼수 있습니다. istio-proxy 컨테이너의 /stats 엔드포인트로 메트릭 조회가 가능합니다.
| kubectl exec -it deploy/{webapp} -c istio-proxy \ -- curl localhost:15000/stats |
curl이 구현되지 않는 distroless 이미지(

Harden Docker Container Images )의 경우 pilot-agent 명령을 이용해서 쿼리할 수 있습니다.
| kubectl exec -it deploy/{webapp} -c istio-proxy \ -- pilot-agent request GET stats |
결과에서 istio_requests_total 메트릭과 istio_request_duration_milliseconds 같은 히스토그램을 확인할 수 있습니다. Standard 메트릭은 다음 링크에서 확인할 수 있습니다. (https://istio.io/latest/docs/reference/config/metrics/)
- istio_requests_total
- istio_request_bytes
- istio_response_bytes
- istio_request_duration
- istio_request_duration_milliseconds
proxy 개수가 증가하고 메트릭 수집이 증가함에 따라 prometheus와 같은 시스템이 부하를 받을수 있기 때문에 아래 내용처럼 matcher를 활용하여 부하를 줄일 필요가 있습니다. (https://istio.io/latest/docs/reference/config/istio.mesh.v1alpha1/#ProxyConfig-ProxyStatsMatcher)
Cluster Profile meshConfig 에 구성하는 방식은 다음 패턴과 같은 예시로 사용이 가능합니다.
| apiVersion: install.istio.io/v1alpha1 kind: IstioOperator metadata: name: control-plane spec: profile: demo meshConfig: defaultConfig: proxyStatsMatcher: inclusionPrefixes: - "cluster.outbound|80||datasync.app-app" |
proxy.istio.io/config annotation 구성을 통해 app별로 동일하게 적용이 가능합니다.
| metadata: annotations: proxy.istio.io/config: |- proxyStatsMatcher: inclusionPrefixes: - "cluster.outbound|80||datasync.app-app" |
Control Plane metrics
컨트롤 플레인은 다양한 데이터 플레인 프록시와 구성을 동기화한 횟수, 구성 동기화에 걸리는 시간, 잘못된 구성, 인증서 issuance/rotation 등과 같은 정보를 유지합니다.
기본적인 컨트롤 플레인 메트릭을 확인하는 방법은 다음과 같습니다.
| kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics |
CRSs(Certificate Signing Requests) 메트릭을 통해 컨트롤 플레인에서의 요청되고 발행되는 인증서에 대한 현황을 확인할 수 있습니다. (https://kubernetes.io/docs/reference/access-authn-authz/certificate-signing-requests/), (https://istio.io/latest/docs/tasks/security/cert-management/custom-ca-k8s/)
| citadel_server_root_cert_expiry_timestamp 1.933249372e+09 citadel_server_csr_count 55 citadel_server_success_cert_issuance_count 55 |
istio build 정보를 메트릭 레이블에서 확인이 가능합니다.
| kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics | grep build # HELP istio_build Istio component build info # TYPE istio_build gauge istio_build{component="pilot",tag="1.13.2"} 1 |
데이터 플레인 istio-proxy에 구성을 push 하고 컨트롤 플레인이 동기화하는 시간에 대한 histogram을 확인할 수 있습니다. 아래 예시에서 전체 169개 이벤트중에 0.1 초 미만(le 레이블)에 발생하는 통계값은 169개로 확인됩니다. 추후 해당 메트릭을 통한 policy 또는 구성 업데이트 지연이 발생하는 비율을 참고할 수 있습니다.
| kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics | grep pilot_proxy_convergence_time_bucket pilot_proxy_convergence_time_bucket{le="0.1"} 169 pilot_proxy_convergence_time_bucket{le="0.5"} 169 pilot_proxy_convergence_time_bucket{le="1"} 169 pilot_proxy_convergence_time_bucket{le="3"} 169 pilot_proxy_convergence_time_bucket{le="5"} 169 pilot_proxy_convergence_time_bucket{le="10"} 169 pilot_proxy_convergence_time_bucket{le="20"} 169 pilot_proxy_convergence_time_bucket{le="30"} 169 pilot_proxy_convergence_time_bucket{le="+Inf"} 169 |
서비스의 개수와 VirtualService 리소스가 얼마나 생성되었는지 proxy의 개수는 몇개인지 확인할 수 있습니다.
| # HELP pilot_services Total services known to pilot. # TYPE pilot_services gauge pilot_services 52 # HELP pilot_virt_services Total virtual services known to pilot. # TYPE pilot_virt_services gauge pilot_virt_services 1 # HELP pilot_vservice_dup_domain Virtual services with dup domains. # TYPE pilot_vservice_dup_domain gauge pilot_vservice_dup_domain 0 # HELP pilot_xds Number of endpoints connected to this pilot using XDS. # TYPE pilot_xds gauge pilot_xds{version="1.13.2"} 7 |
xDS API 의 업데이트 수도 확인할 수 있습니다.
- cluster discovery (CDS)
- endpoint discovery (EDS)
- listener and route discovery (LDS/RDS)
- secret discovery (SDS)
| kubectl exec -it -n istio-system deploy/istiod -- curl localhost:15014/metrics | grep pilot_xds_pushes # HELP pilot_xds_pushes Pilot build and send errors for lds, rds, cds and eds. # TYPE pilot_xds_pushes counter pilot_xds_pushes{type="cds"} 140 pilot_xds_pushes{type="eds"} 222 pilot_xds_pushes{type="lds"} 140 pilot_xds_pushes{type="rds"} 143 |
Istio metrics with Prometheus
메트릭은 istio-proxy가 prometheus format으로 expose 하는 값을 확인할 수 있습니다.
| kubectl exec -it deploy/webapp -c istio-proxy \ -- curl localhost:15090/stats/prometheus |
Prometheus가 메트릭을 수집하는 패턴은 다음과 같습니다.(https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/design.md)
Istio의 메트릭 스크랩을 위해 ServiceMonitor 와 PodMonitor 리소스를 생성합니다.
| apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: name: envoy-stats-monitor namespace: istio-system labels: monitoring: istio-proxies release: prometheus spec: selector: matchExpressions: - {key: istio-prometheus-ignore, operator: DoesNotExist} namespaceSelector: any: true jobLabel: envoy-stats podMetricsEndpoints: - path: /stats/prometheus interval: 15s relabelings: - action: keep sourceLabels: [__meta_kubernetes_pod_container_name] regex: "istio-proxy" - action: keep sourceLabels: [__meta_kubernetes_pod_annotationpresent_prometheus_io_scrape] - sourceLabels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 targetLabel: __address__ - action: labeldrop regex: "__meta_kubernetes_pod_label_(.+)" - sourceLabels: [__meta_kubernetes_namespace] action: replace targetLabel: namespace - sourceLabels: [__meta_kubernetes_pod_name] action: replace targetLabel: pod_name |
| apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: istio-component-monitor namespace: istio-system labels: monitoring: istio-components release: prometheus spec: jobLabel: istio targetLabels: [app] selector: matchExpressions: - {key: istio, operator: In, values: [pilot]} namespaceSelector: any: true endpoints: - port: http-monitoring interval: 15s |
prometheus에서 target auto-discovery를 위해 metadata.labels.release 를 match 시킬수 있도록 이미 구성된 prometheus stack의 label prometheus 와 일치 시킵니다.
| apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: istio-component-monitor namespace: istio-system labels: monitoring: istio-components release: prometheus spec: jobLabel: istio targetLabels: [app] selector: matchExpressions: - {key: istio, operator: In, values: [pilot]} namespaceSelector: any: true endpoints: - port: http-monitoring interval: 15s --- apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: name: envoy-stats-monitor namespace: istio-system labels: monitoring: istio-proxies release: prometheus spec: selector: matchExpressions: - {key: istio-prometheus-ignore, operator: DoesNotExist} namespaceSelector: any: true jobLabel: envoy-stats podMetricsEndpoints: - path: /stats/prometheus interval: 15s relabelings: - action: keep sourceLabels: [__meta_kubernetes_pod_container_name] regex: "istio-proxy" - action: keep sourceLabels: [__meta_kubernetes_pod_annotationpresent_prometheus_io_scrape] - sourceLabels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 targetLabel: __address__ - action: labeldrop regex: "__meta_kubernetes_pod_label_(.+)" - sourceLabels: [__meta_kubernetes_namespace] action: replace targetLabel: namespace - sourceLabels: [__meta_kubernetes_pod_name] action: replace targetLabel: pod_name |
ServiceMonitor 와 PodMonitor 타겟 등록 여부를 확인합니다.
- envoy-stats-monitor - 데이터 플레인
- istio-component-monitor - 컨트롤 플레인
Istio’s standard metrics
메트릭은 서비스 호출 간(인바운드/아웃바운드) 텔레메트리의 counter, gauge 또는 distribution/histogram입니다. 예를 들어, istio_requests_total 메트릭은 서비스에 대한 총 요청(인바운드) 또는 서비스에서 발생한 총 요청 수를 계산합니다. 서비스에 인바운드 및 아웃바운드 요청이 모두 있는 경우 istio_requests_total 메트릭에 대한 두 가지 항목이 표시됩니다.
(https://istio.io/latest/docs/reference/config/metrics/)
- istio_requests_total - (counter) istio-proxy 요청에 대한 증분 카운터
- istio_request_bytes - (distribution/histogram) 요청 body sizes 분포
- istio_response_bytes - (distribution/histogram) 응답 body sizes 분포
- istio_request_duration_milliseconds - (distribution/histogram) 요청의 기간에 대한 분포
- istio_request_messages_total - (counter) 클라이언트에서 보내진 gRPC message 증분 카운터
- istio_response_messages_total - (counter) 서버에서 보내진 gRPC message 증분 카운터
Istio’s custom metrics
Attributes — envoy 1.25.0-dev-4fb3ee documentation
Attributes refer to contextual properties provided by Envoy during request and connection processing. They are named by a dot-separated path (e.g. request.path), have a fixed type (e.g. string or int), and may be absent or present depending on the context.
www.envoyproxy.io
Logging
istio 로깅은 Envoy Access Logging 포맷을 기본으로 합니다.
configuration profile이 `demo` 로 되어 있는 경우에만 egress gateway와 access logging이 활성화가 됩니다. 그외의 profile에서 활성화를 위해서는Telemetry API 와 Mesh Config 를 통해 구성이 가능합니다.
Using Telemetry API
Telemetry API 리소스는 Istio 상위 리소스에서 구성을 상속합니다. 아래와 같이 root configruation namespace인 istio-system에 선언을 하면 하위 namespace에서 상속됩니다.
| apiVersion: telemetry.istio.io/v1alpha1 kind: Telemetry metadata: name: mesh-default namespace: istio-system spec: accessLogging: - providers: - name: envoy |
IstioOperator Custom Resource를 사용할 경우 다음과 같이 values에 추가합니다.
| spec: meshConfig: accessLogFile: /dev/stdout accessLogEncoding: "JSON" #accessLogFormat: {} |
Helm Chart 구성일 경우에는 다음과 같이 추가합니다.
| meshConfig: accessLogFile: /dev/stdout accessLogEncoding: "JSON" #accessLogFormat: {} |
CLI로 추가할 경우는 istioctl 로 설정합니다.
| istioctl install --set meshConfig.accessLogFile=/dev/stdout |
meshConfig.accessLogEncoding 의 경우는 JSON 또는 TEXT로 선택할 수 있습니다.
meshConfig.accessLogFormat 의 경우는 Envoy Access Logging 포맷을 참고하여 추가 설정가능합니다.
access log flag는 Envoy에서 명령 연산자(command operator)라고 합니다. 정의에 따라 액세스 로그에 삽입될 값을 추출할 수 있습니다.
TEXT 형식의 default access log format은 다음과 같습니다.
| [%START_TIME%] \"%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%\" %RESPONSE_CODE% %RESPONSE_FLAGS% %RESPONSE_CODE_DETAILS% %CONNECTION_TERMINATION_DETAILS% \"%UPSTREAM_TRANSPORT_FAILURE_REASON%\" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% \"%REQ(X-FORWARDED-FOR)%\" \"%REQ(USER-AGENT)%\" \"%REQ(X-REQUEST-ID)%\" \"%REQ(:AUTHORITY)%\" \"%UPSTREAM_HOST%\" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%\n |
- %START_TIME% - 밀리초를 포함한 요청 시작 시간
- %REQ(:METHOD)% - 요청에 사용된 메소드
- %BYTES_RECEIVED% - Body 수신 bytes
- %PROTOCOL% - HTTP/1.1 or HTTP/2 or HTTP/3
- %RESPONSE_CODE% - HTTP responce 코드, responce 코드 0 는 서버가 응답 시작을 보내지 않았음을 의미합니다. 이것은 일반적으로 다운 스트림 클라이언트가 연결이 끊어 졌음을 의미합니다.
- %RESPONSE_CODE_DETAILS% - HTTP responce 코드 세부 정보는 응답 코드에 대한 추가 정보를 제공합니다.
- %CONNECTION_TERMINATION_DETAILS% - Envoy가 연결을 종료한 이유에 대한 추가 정보를 제공할 수 있습니다.
- %DURATION% - 시작 시간부터 마지막 바이트 출력까지의 총 요청 기간(밀리초)
- %RESPONSE_DURATION% - 업스트림 호스트에서 읽은 첫 번째 바이트부터 다운스트림으로 보낸 마지막 바이트까지의 총 요청 기간(밀리초)입니다.
- %RESPONSE_FLAGS% - responce 또는 connection에 대한 추가 세부 정보. TCP 연결의 경우 설명에서 언급 된 responce 코드가 적용되지 않습니다.
- HTTP and TCP
- UH: No healthy upstream hosts in upstream cluster in addition to 503 response code.
- UF: Upstream connection failure in addition to 503 response code.
- UO: Upstream overflow (circuit breaking) in addition to 503 response code.
- NR: No route configured for a given request in addition to 404 response code, or no matching filter chain for a downstream connection.
- URX: The request was rejected because the upstream retry limit (HTTP) or maximum connect attempts (TCP) was reached.
- NC: Upstream cluster not found.
- DT: When a request or connection exceeded max_connection_duration or max_downstream_connection_duration.
- HTTP only
- DC: Downstream connection termination.
- LH: Local service failed health check request in addition to 503 response code.
- UT: Upstream request timeout in addition to 504 response code.
- LR: Connection local reset in addition to 503 response code.
- UR: Upstream remote reset in addition to 503 response code.
- UC: Upstream connection termination in addition to 503 response code.
- DI: The request processing was delayed for a period specified via fault injection.
- FI: The request was aborted with a response code specified via fault injection.
- RL: The request was ratelimited locally by the HTTP rate limit filter in addition to 429 response code.
- UAEX: The request was denied by the external authorization service.
- RLSE: The request was rejected because there was an error in rate limit service.
- IH: The request was rejected because it set an invalid value for a strictly-checked header in addition to 400 response code.
- SI: Stream idle timeout in addition to 408 response code.
- DPE: The downstream request had an HTTP protocol error.
- UPE: The upstream response had an HTTP protocol error.
- UMSDR: The upstream request reached max stream duration.
- OM: Overload Manager terminated the request.
- DF: The request was terminated due to DNS resolution failure.
- %ROUTE_NAME% - 라우트 이름
- %UPSTREAM_HOST% - 업스트림 host URL
- %DOWNSTREAM_REMOTE_ADDRESS% - 다운스트림 연결의 리모트 주소
- %DOWNSTREAM_LOCAL_URI_SAN% - 다운 스트림 TLS 연결을 설정하는 데 사용되는 로컬 인증서의 SAN에 존재하는 URI
helm upgrade를 통해 values 를 변경하여 재배포를 진행합니다.
| meshConfig: accessLogFile: /dev/stdout accessLogEncoding: JSON accessLogFormat: | { # Request start time including milliseconds. systemTime: '%START_TIME%' # Bytes Received in the request body bytesReceived: '%BYTES_RECEIVED%' # Request Method httpMethod: '%REQ(:METHOD)%' # Protocol. Currently either HTTP/1.1 or HTTP/2. protocol: '%PROTOCOL%' # HTTP response code. Note that a response code of ‘0’ means that the server never sent the # beginning of a response. This generally means that the (downstream) client disconnected. responseCode: '%RESPONSE_CODE%' # Total duration in milliseconds of the request from the start time to the last byte out clientDuration: '%DURATION%' # HTTP Response code details responseCodeDetails: '%RESPONSE_CODE_DETAILS%' # Connection termination details connectionTerminationDetails: '%CONNECTION_TERMINATION_DETAILS%' # Total duration in milliseconds of the request from the start time to the first byte read from the upstream host targetDuration: '%RESPONSE_DURATION%' # Value of the "x-envoy-original-path" header (falls back to "path" header if not present) path: '%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%' # Upstream cluster to which the upstream host belongs to upstreamName: '%UPSTREAM_CLUSTER%' # Unique tracking ID requestId: '%REQ(X-REQUEST-ID)%' # Response flags; will contain details about the response or connectiuon responseFlags: '%RESPONSE_FLAGS%' # Name of the route routeName: `%ROUTE_NAME%` # Remote address of the requester downstreamRemoteAddress: '%DOWNSTREAM_REMOTE_ADDRESS%' # Upstream host url upstreamHost: '%UPSTREAM_HOST%' # URIs present on the SAN of the local certificate used to establish downstream TLS downstreamLocalURISan: '%DOWNSTREAM_LOCAL_URI_SAN%' } |
| helm upgrade istiod istio/istiod -n istio-system -f ./add-on/istio/istiod/dev-values.yaml |
'고기 대신 SW 한점 > Public Cloud' 카테고리의 다른 글
| Autoscaling+HPA - Instance Type Profiling (0) | 2023.02.01 |
|---|---|
| AWS PostgreSQL, Fast Failover 방법 (0) | 2023.01.26 |
| [Public Cloud] Pod test (0) | 2023.01.10 |
| [Public Cloud] Kyverno ? (0) | 2023.01.10 |
| [AWS] LandingZone - VPC Design (1) | 2023.01.06 |